
從過往的建置經驗來歸納,我們大致可以整理出來自管理階層與技術人員這兩個不同位階的問題:
• 對於管理階層來說,他們通常會問諸如『GPU Server 買了,誰能告訴我然後呢?』、『錢是砸了,怎麼搞那麼久還沒看到上線運行?』、『我聽你們的建議買了這麼高規格的設備,誰能告訴我究竟成效在哪裡?』這類的問題。
• 然而技術人員則更為關注『為甚麼 GPU 總是用不滿?但排程還是很多…』、『是否可以整合現有的工作流程,怎樣才能順利進行?』、『看文件都需要 K8S,我們都沒人會怎麼辦?』這類技術問題。
歸根結底,大部分問題主要是由於 AI 導入的複雜性以及缺乏實務經驗(可參考的公開實務資訊不多)所致。其實這與 Nvidia 官方所做的統計調查非常一致:
| 現階段實際真的導入在生產環境的比例仍然偏低,主要障礙來自於複雜性與成熟度這兩個方面。 |
 現階段企業 AI 導入現況
現階段企業 AI 導入現況
挑戰是往往在企業採購了 GPU 設備之後才開始的:如何最大化地發揮運算資源是橫梗在所有工程旅途中首當其衝要解決的難關。換而言之,在當今速度致勝的資訊年代,我們必須將每一點滴的 GPU 資源充分利壓榨到極致,才能保證我們的投資效益最大化、才不至於在如火如荼的 AI 賽道上敬陪末座。
當然了,綜合資源管理上除了 GPU 之外,其他像是 CPU、DPU、Networking、Storage 等等資源也是非常重要的。只是礙於篇幅關係,本文主要集中在 GPU 方面的資源管理介紹。
首先,我們來談談 GPU 資源分配,常見模式有如下這些選擇:
• 整張分配(Whole-card passthrough)
把整個實體 GPU(或多張 GPU)完整交給單一 VM / 容器 / Job 使用
• 多張合併(GPU aggregation)
把多張 GPU 聚合成同一個作業可用(單主機內或跨主機分散式訓練)
• 單張切割(Partitioning / vGPU / MIG)
把一張 GPU 切成多個較小的實例分配給多個使用者或容器(硬體或軟體切割)
• 分時共享(Time-sliced sharing)
多個 workload 交替使用同一張 GPU(軟體層排隊/多工),非硬隔離
• 虛擬化 vGPU(NVIDIA vGPU / mdev)
提供接近硬隔離的虛擬 GPU 實例(通常需廠商軟體 + 授權)
接下來我們針對這幾種主要模式來展開說明。
這種模式常見於虛擬環境的場景。
基本使用的技術就是 PCIe passthrough / device pass-through,例如虛擬機用 QEMU/KVM 的 hostdev、ESXi 的 DirectPath、或 Hyper-V 的 DDA)。若使用容器技術的話,則可直接把 /dev/nvidia* 裝置映射到容器裡面。
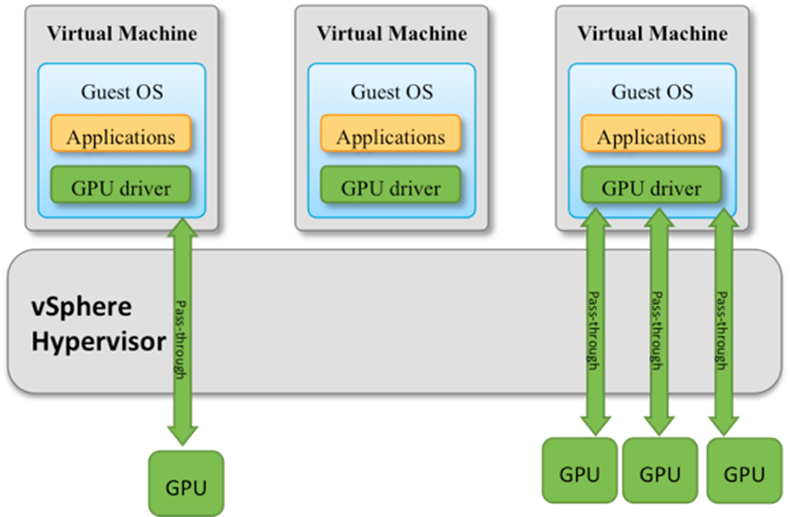 透過 pass-through 技術可以將一張或多張 GPU 分配給 VM 獨享
透過 pass-through 技術可以將一張或多張 GPU 分配給 VM 獨享
整張分配模式適用於需要完整效能與 CUDA 驅動存取、尤其是高吞吐訓練、單一使用者專用的應用場景。最大的優勢是效能近裸機、隔離簡單。然而缺點則是資源利用率低、無法細粒度分享:當整片卡未被用滿時就會造成資源浪費。
要實現多張合併,主要有如下兩個層級:
• 單機:使用 NVLink 或 NVSwitch 提升 GPU 間帶寬(需硬體支援),對大型 DNN 訓練特別關鍵。
• 跨機:使用分散式訓練框架(Horovod、PyTorch DDP、TensorFlow MirroredStrategy)搭配 NCCL 通訊,透過 RDMA(InfiniBand 或 RoCE)實現多台主機 GPU 協同作業。
若系統採用 NVIDIA NVLink Switch System(例如 DGX GH200),則可在多機間延伸 NVLink Fabric。
 透過 NVLink 群聯提升 GPU 帶寬
透過 NVLink 群聯提升 GPU 帶寬
不是所有跨機 GPU 通訊都需要 NVLink 協定:
• 傳統分散式訓練路徑:透過 RDMA(InfiniBand 或 RoCE);
• 專用 NVLink Switch System:這是新一代(例如 DGX H200/B200 SuperPOD)架構才有的「多機 NVLink」。
| 簡單歸納:一般 HPC / AI 集群用 RDMA + NCCL;NVIDIA 特製系統(DGX GB200 / NVLink Switch System)才用 NVLink Fabric 跨主機。 |
這裡與前面的多張 GPU 合併相反:將單張 GPU 切割成多張來使用。如果說合併是因為一張 GPU 不夠用,那切割就是一張 GPU 用不滿,其實跟 VM 的概念非常類似。
常見的 Nvidia GPU 切割方案有:
• MIG(Multi-Instance GPU)
硬體層級切割成多個隔離實例(不同的 compute/memory slices),每個實例都有獨立的上下文與隔離。延遲低,適合多租戶推理或小型訓練。在 Nvidia 的 GPU 卡系列中,只有 Ampere / Hopper / Blackwell 等系列支援 MIG ,且最多只能切出 7 個 GPU instance (Blackwell 架構雖採用 8 組 HBM3e 記憶體通道,但在 MIG 模式下仍只支援最多 7 個 Compute Slice)。
• vGPU(GRID / Virtual Compute Server)
透過 NVIDIA 的驅動/管理軟體在 Host 上提供多個 vGPU profile(需授權),常用於 VDI 與虛擬化工作負載。
• MPS(Multi-Process Service)
軟體層面的 GPU sharing(容器/作業排隊),能讓多進程共享同一 GPU 的 CUDA context(主要提升多小任務吞吐),但不是隔離。
針對前述提到的幾種 GPU 資源分配方式,我們整理為下表:
 Tab-1: GPU 資源分配方式
Tab-1: GPU 資源分配方式
這裡我們特別展開 vGPU 方案來跟大家說一下如何更有效地將有限的 GPU 資源分享給多租戶使用。
一般來說,使用 vGPU 方案的 workload 需要一定的隔離性,但又不需要用到整顆資源。但需要確認 GPU 型號可支援 vGPU 切割,且已經取得適當授權資格。
vGPU 是在 Hypervisor 層進行切割管理,一旦使用 vGPU 模式後,主機上即無法收集 GPU 資訊。然後再根據 GPU 型號透過不同的 profile 分配給 VM 使用。然而 vGPU 並非完全隔離的,它僅確保了 Memory Frame Buffer,若同時有其他佔用過量運算資源的程式, vGPU 間效能可能會相互影響。
想確認 GPU 型號是否支援 vGPU,參考 Nvidia 的官方網站:
https://docs.nvidia.com/ai-enterprise/release-7/7.1/support/support-matrix.html#supported-nvidia-gpus-and-networking
另外,我們也需要確認所使用的 Hypervisor 是否獲得 NVIDIA 官方提供支援。截至本文 (2025/10) 最新版本的 vGPU Driver 為 v19.2,NVIDIA 官方明確支援的 Hypervisor 選項如下:
• Microsoft Azure Local Support
• Microsoft Windows Server Support
• Red Hat Enterprise Linux with KVM Support
在早期,MIG 與 vGPU 是不能同時啟用的。然而 Nvidia 最新發表的 RTX Pro6000 Blackwell Server Edition (BSE) 這一型號卻同時將這兩種技術揉合在一起支援了,可以讓單一一片 RTX Pro6000 BSE 顯卡支援高達 48 台 VM!這無疑是 Nvidia vGPU 技術應用上的一個重大突破。
 MIG-Backed vGPU 提供更彈性的資源分配支援
MIG-Backed vGPU 提供更彈性的資源分配支援
透過 MIG-Backed vGPU 技術,我們可以獲得更細膩的顆粒度支援,更靈活的根據不同應用需求場景提供更為彈性的分配方案。
並非所有 GPU 型號都支援 MIG-Backed vGPU。 就拿同樣的 RTX Pro6000 Blackwell 系列的 GPU 來說,Workstation Edition 目前就完全不支援 vGPU!老實說,剛得到這個確認的時候我們還真的蠻訝異的。 此外,Nvidia 最新版 vGPU-v19 目前也只有 KVM 這個 hypervisor 可以完整支援 MIG-Backed Time-Sliced vGPU,據說 vSphere v9、Azure Local、Windows 2025 Server 要在 2026 Q1 才會支援。 |
Nvidia 針對不同的使用者族群,提供了三種不同的授權類別:
• NVIDIA vApps 虛擬應用 (Virtual Applications)
適用於部署 XenApp、Horizon Apps 或其他 RDSH 解決方案的企業。在完整效能下提供 Windows 應用程式而設計。
• NVIDIA vPC 虛擬桌面 (Virtual PC)
適用於需要虛擬桌面並希望獲得優異使用體驗的使用者,可充分運用 Windows 應用程式、瀏覽器及高畫質影片。
• NVIDIA RTX vWS 虛擬工作站 (NVIDIA RTX Virtual Workstation)
適用於希望能遠端使用專業級圖形應用程式的使用者,在任何裝置上皆可享有完整效能與體驗。
• NVIDIA AI Enterprise (AIE)
企業級 AI 平台(軟體 + 授權)內含驅動、NGC 容器、企業支援,包含完整 AI framework 與支援。主要運用 Data center GPU 集中訓練/推論平台、企業 AI 管理、Kubernetes 部署等場合(桌面支援需額外 vGPU/vWS 授權)。
|
伴隨 RTX Pro6000 Blackwell 晶片的發表,Nvidia 還同時提供了另外一個 vGPU 授權 — — vCS (C‑Series / Virtual Compute Server) 。 vCS 介乎於 vWS 與 AIE 授權之間,僅支援純運算(AI / Deep Learning)虛擬化,不提供高階圖形運算。主要針對 compute workloads 而非圖形用途,適合 AI 訓練/推論、HPC、容器化 compute 虛擬機這類型的應用場景。 |
然而,很多人(包括筆者)一開始面對如何採購這些授權往往摸不著頭緒。我們可以透過如下的選擇流程挑選適合的授權:
 Nvidia vGPU 授權決策流程
Nvidia vGPU 授權決策流程
簡單來說主要是如下兩點:
1. 如果不需要 CUDA: 解析度超過 4K 那就要購買 vWS, 不超過 4K 就購買 vPC
2. 如果需要 CUDA:需要 AI 負載且用於生產環境就需要購買 AIE, 否則就購買 vWS
基本上,想要獲得 Nvidia 完整的桌面應用與企業軟體,vWS 搭配 AIE 授權才是最完整的。如下我們針對這兩個授權來做一個比較:
 Tab-2: vWS 授權與 AIE 授權比較
Tab-2: vWS 授權與 AIE 授權比較
|
最新消息: 就在本文撰寫的時候(10/27),Nvidia 公布了一項重磅消息:Nvidia 將 AI Enterprise (AIE) 與 Omniverse Enterprise 這兩項企業授權合二為一(而且無需加價)!合併後的授權稱作 Nvidia Enterprise (NVE) 。 |
與 vGPU 授權密切相關的另一個概念就是 vGPU Profile。當我們在進行 GPU 切割設定的時候,需要指定相應的 Profile 才能工作。
如下是一個 Profile 的範例:
 Nvidia vGPU Profile
Nvidia vGPU Profile
關於 vGPU Profile 的解讀如下:
1. 第一個字母表示 GPU 的架構,例如: H(Hopper)、L(Lovelace)、B(Blackwell)。
2. 第二個數字(或到 — 之間)代表型號,例如 4、40、40S。
3. 在 — 之後的第一組數字代表 Memory Frame Buffer ,也就是 GPU 記憶體大小,單位是 G。
4. 最後一個字母代表相應的授權,例如:A(vApp)、B(vPC)、Q(vWS)。
|
再次提醒: 不同的 GPU 型號所支援的 Profile 都不盡相同。設定之前請到 Nvidia 官方技術文件網站確認,或諮詢供應商。 |
通常來說,我們會根據應用負責來決定適當的 Profile,尤其是記憶體的大小。以 RTX Pro6000 BSE 為例:
 根據應用與模型大小分配資源
根據應用與模型大小分配資源
再次強調,vGPU 通常是用來切個單一 GPU 、並不是用來合併多顆 GPU 的。技術上,我們的確可以透過多個 Profile 為一台 VM 分配超過一顆 GPU 資源:
 透過多個 Profile 分配 GPU 資源
透過多個 Profile 分配 GPU 資源
上例中我們將 1.5 顆 L40S 分配給一台 VM,然而需要注意的是:這種分配與 Pass-Though 技術不一樣。透過多個 vGPU Profile 貌似分配了超過一片資源給到 VM,但這僅是記憶體容量上的增加,事實上並非真正的合併了 1.5 片的 GPU 算力。
請參考前面的介紹,真正的合併需要 GPU 型號本身支援 NVLink 技術,更適合透過 pass-through 或 MIG 的方式進行實作。
|
題外話: 近期常看到有不少用戶對 DGX Spark (GB10) 兩台串聯的技術存在誤解。其實跟這裡提到的多個 profile 分配的情況差不多:都只是單純記憶體的增加而已,並非真正意義的 GPU 算力合併。 |
有一定容器化經驗的團隊,其實更建議選用 Kubernetes 來分配 GPU。
|
Nvidia 原廠目前所推出的最新 AI 解決方案,幾乎都是架構在 K8S 平台之上。關於這一生態趨勢請參考我們另外一片專欄文章:當代企業 AI 應用導入策略 |
在 Kubernetes 上,GPU 可以被當作 cpu/memory 等硬體資源一樣分配給 container 使用,可透過 GPU operator 完成在 kubernetes 上的套件安裝:

根據我們的經驗,在 K8S 分配 GPU 更為簡單明瞭。只是,我們需要注意 GPU 資源分配模式就是了:
 Tab-3: K8S GPU 資源分配模式
Tab-3: K8S GPU 資源分配模式
其中最基本的考量是:
• 是否需要分配多張 GPU 給單一的 Pod?
如果這個答案是 YES,那就不能啟動 MIG、Time-Slicing、MPS 這幾種模式,而是回到 GPU Operator 的預設模式(獨佔模式)才能在 YAML 中設定超過 1 顆 GPU 的資源:

若非獨佔模式的設定下,您會遇到如下這樣的錯誤:

Kubernetes GPU Pool 這個概念其實是跨機 GPU 管理與調度的核心實踐方式之一,特別是在多『GPU 跨機協同』的場景下。
簡單來說,GPU Pool 是 Kubernetes 在多節點環境中,透過 NVIDIA GPU Operator / device plugin / scheduler 建立的一個虛擬 GPU 資源池。這個池子把多台伺服器裡的實體 GPU 都整合成 Kubernetes 邏輯資源的一部分。在這種設計下,使用者(或訓練任務)可以像申請 CPU、RAM 一樣申請資源,K8S 就會自動幫你分配哪台機器的哪幾張 GPU。
跨機協同運算(例如 DNN 分散式訓練)本身不依賴 NVLink,而是依賴:
• NCCL (NVIDIA Collective Communication Library):在多 GPU / 多節點間負責高效通訊。
• 高速網路 (InfiniBand / RoCE / RDMA):提供接近 NVLink 級別的節點間帶寬。
• 訓練框架層支援 (如 PyTorch DDP, Horovod, TensorFlow MirroredStrategy):負責在軟體層做梯度同步。
Kubernetes 在這裡所扮演的角色:
1. 調度 (Scheduler):分配哪些節點參與訓練。
2. 啟動容器 (Pod):在各節點啟動 GPU-enabled 容器。
3. 網路協調 (Service / MPI Operator / RDMA networking):幫助訓練框架能彼此溝通。
就結果而言,多台機器的 GPU 看起來就像一個大的 pool,但實際是由訓練框架透過 NCCL/InfiniBand 讓它們協同工作。這個層級上,不需要 NVLink(那是單機 GPU 間的直連技術)。
相較 K8S GPU Pool 這種資源抽象化的概念來說,在跨機 GPU 資源運用上 NVLink Fabric 還是有其優勢的。兩者的關鍵差異在於資料一致性與延遲:
 Tab-4: NVLink Fabric 與 K8S GPU Pool 比較
Tab-4: NVLink Fabric 與 K8S GPU Pool 比較
NVLink Fabric 跨主機的優勢在於提供近乎單機等級的延遲與共享記憶體架構,讓多張 GPU 以「一張超級 GPU」的方式協作。K8s GPU Pool 的優勢則在於分散式管理與彈性編排,可跨節點甚至跨資料中心調度 GPU 資源。
如果軟硬體條件完備,我們也是可以在 NVLink Fabric 的環境下將大型的 K8S 工作部署在同一個 frabic domain 的 node group 中。只是需要準備的設備及設定會複雜許多:
• 硬體
- NVLink Switch System / NVLink Fabric(例如 NVL72 / NVSwitch 機櫃)已正確佈線、switch 與 GPU 互連並啟動。
- 若是 NVL72 之類邏輯整櫃域(single fabric),確認廠商是否將該櫃暴露為單一或多個 node(有些系統會把整櫃當作一個邏輯系統)。
• 驅動與管理軟體
- 安裝相容的 NVIDIA Driver(版本需支援該 Fabric 與 CUDA/NCCL 版本)。
- 安裝/啟用 NVIDIA Fabric Manager(或廠商等效服務),以管理 NVSwitch / NVLink fabric。Fabric Manager 常以 systemd 服務或 daemonset 方式在每台 node 運行(視硬體而定)。
• 通訊庫
- NCCL(建議最新穩定)、UCX(若使用 UCX transport),並確認 NCCL 支援 NVLink Fabric。
• 網路
- 仍需高速網路(InfiniBand/Quantum or RoCE)作控制通訊與 fallback 傳輸(視架構而定)。
同時,K8S Cluster 也需要正確配置好相關的 Operator 與 Driver,且確保 CUDA runtime 正常運行(或透過 DaemonSet 來注入 driver 容器),某些硬體甚至需要在 node 層運行 Fabric Manager。
當企業採購了高階的圖形處理伺服器之後,接下來就必須思考『如何讓多個使用者同時線上作業?』這個問題。這就需要 VDI 方案了。
 企業 VDI 常規架構
企業 VDI 常規架構
通常來說,需要 VDI 的用戶很大機會是需要集中處理大量的圖形運算/交換的場景,例如 3D 繪圖、光影追蹤、數位孿生等視覺運算,通常這種工作都無可避免地需要用到 GPU 加速處理。最經典的的應用就是 Nvidia Omniverse 平台上面的各種工作負載與應用程式。
|
注意: 在設計 VDI 基礎架構時,必須特別注意所使用的遠端桌面協議是否支援圖形加速處理,光靠 RDP/VNC 這類傳統遠端桌面協議是無法做到的。 |
市面上的 VDI 方案很多,主要分 Open-Source 與商用套件兩個陣營,針對企業 AI 應用我們會建議後者。以近年來廣受歡迎的 PVE 為例,即使 PVE 本身可以將 GPU 資源透過 pass-through 或 vGPU Profile 分配給 VM,但還是需要搭配支援圖形加速的 VDI 用戶端才能真正發揮 GPU 的加速效果。例如:HP Anyware (PCoIP)、Parsec / Sunshine / Moonlight、Citrix VDA + HDX 3D Pro、VMware Horizon Agent + Blast Extreme / PCoIP、等等方案,而且大部分產品依然是商用套件。
就我們的經驗來說,目前運用起來整合最完整、問題最少的 VDI 方案是 Omnissa Horizon (VVF for VDI)。主要優勢有兩點:
• Horizon 透過 vCenter API 全自動佈署 / 分派桌面 / 管理 GPU Profiles
• 不需手動設定 libvirt、QEMU、PCI passthrough 等複雜流程
|
Omnissa Horizon (VVF for VDI) 方案本身是包含 vSphere Enterprise Plus 與 vCenter Server 授權的。換句話說您不需要再額外添購上述授權就可以直接安裝部署。 但是,此授權方案只能部署 VDI 桌面,不可運行伺服器型 VM!也就是說你所部署的 VM 不能用當作常規服務器使用,而且是按照 per named user / concurrent user 計價。 |
此外還有其他一些軟體搭配上的限制:
• 整合要求:必須使用 Omnissa Horizon (含 Connection Server)
• Hypervisor:僅支援 VMware ESXi(VVF 授權內含)
• 版本相依性:Horizon、vCenter、ESXi 版本需匹配(如 8.15.x / 8.0U3 等)
假設我們選用了 Horizon 作為我們的 VDI Client,不妨拿VVF VDI 與 PVE + Horizon 這兩個方案來做個比較:
 Tab-5: PVE + Horizon 與 VVF VDI 的比較
Tab-5: PVE + Horizon 與 VVF VDI 的比較
由此可見,如果我們要做的目標是『提供 GPU 加速的 VDI 桌面(例如工程繪圖、3D 模型、AI 開發)』,那麼使用 VVF for VDI 套件會比 PVE 簡單非常多、穩定度也高。倘若我們的應用場合是 Omniverse 的話,我們可以藉由 Connection Server 分配 GPU VM,並且每人可獨立使用 Omniverse / 3D App,同時有集中管理、登入控制、session broker 等開箱即用的方案了。
企業導入 GPU Server 後,需依據工作負載特性選擇適當的資源分配策略。從整張分配到 vGPU 虛擬化,再到 Kubernetes 的容器化編排,每種方案各有其適用場景。透過硬體分割技術如 MIG、軟體虛擬化方案如 NVIDIA vGPU,以及容器平台的彈性調度機制,企業可在效能、資源利用率與管理複雜度間取得平衡。
GPU 資源管理不僅關乎硬體效能,更影響整體投資報酬。透過適切的分配策略與平台整合,企業能在 AI、K8S 與 VDI 等多場景中達到資源最大化與營運效率提升。
https://www.fibermall.com/blog/nvidia-nvlink-and-nvswitch-evolution.htm
https://docs.nvidia.com/multi-node-nvlink-systems/mnnvl-user-guide/overview.html
https://docs.nvidia.com/datacenter/tesla/mig-user-guide/#
END
聲明:文章圖片主要引用自 Nvidia 官網文件與手冊內容。